Detecting programming languages (or human languages) based on samples of text is a fairly common problem, encountered and solved e.g. in GitHub for various tasks.
But what about doing the same based on images? In this post, I’ll show how to use machine learning to classify images of source codes in a couple of different programming languages.
NB: code and data can be found on Github, especially the Jupyter notebook detailing the modelling and training process.
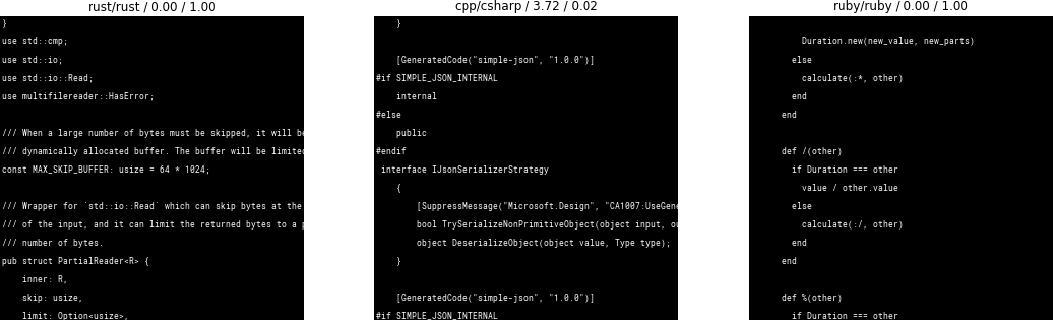
Here’s some Rust and Ruby code being properly identified. C# was mistaken to be C++
Background
I’ve recently been drawn into the machine learning world and started going through the fast.ai online course on deep learning. I like it a lot so far as it provides a very practical, hands-on way of getting started — from the very beginning, you work on pretty practical exercises, gradually building up knowledge of what’s happening behind the scenes without having to ingest a lot of theory in the beginning.
The fast.ai course begins with image classification problems. Specifically it’s about detecting whether there’s a dog or a cat on the image, but you’re encouraged to give it a try with your own images and categories. Various students have taken up on that, building baseball-vs-cricket classifiers and more. I decided to try with source codes from different programming languages.
Wait… for detecting something based on text, shouldn’t you stay text-based? Isn’t it ludicrous to convert the text to image and then work with that, instead of the original source text? Yeah, it sure is, but first, this is just a fun experiment, and second, image classification networks can actually be surprisingly efficient at tasks which aren’t really image-based. Image classifiers have successfully been used for detect specific sounds (e.g. for finding whales or detecting illegal logging), predicting composers of a piece of music, as well as analyzing mouse pointer trails to find fraudulent users.
So let’s see how well they can handle programming languages.
Data Preparation
I started by selecting 8 programming languages — C, C++, C#, Go, Java, Python, Ruby, and Rust.
For each of them, I used Github topics
to find about 8 most popular and representative projects.
I then downloaded code in their master branches and
manually selected roughly 1Mb of source files from each,
finally combining them to one bundle per programming language
(fun fact: all this took more time than training the actual model).
The aim was to keep the resulting bundles balanced,
so that no one project would make up an overwhelmingly big part of the bundle.
Next, I wrote a simple Python script to take ~17-line samples from each of the bundles and render them into simple white-text-on-black-background images. As a result, I ended up with 500 PNG images for each selected language — a total of 4000 images. That should be enough for this experiment.
Sample rendered images — one with Python code and one with Go
Modelling
I started out by using an existing generic image-classification model — ResNet-34 — and applying transfer learning to modify it such that it detects results that I’m interested in.
The fastai library makes such tasks really easy — it only takes a couple of lines of code to load the data, create a model, and train it:
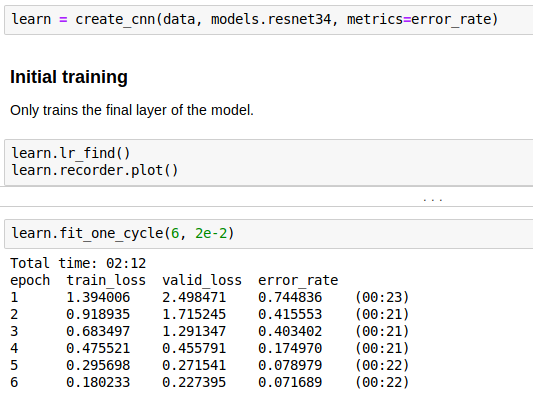
Creating and training a model based on ResNet34 and our data
The model very quickly gets to 92.8% accuracy — surprisingly good result considering that the original model was trained on images that look nothing like source code.
With a bit of extra training, we get a final accuracy of 94.9%.
Exploring the Results
Let’s explore the performance of the model by looking at some results, starting with the confusion matrix. It basically shows which categories were identified as which. Ideally we’d want everything outside the diagonal to be zeroes, since those are the mistaken classifications.
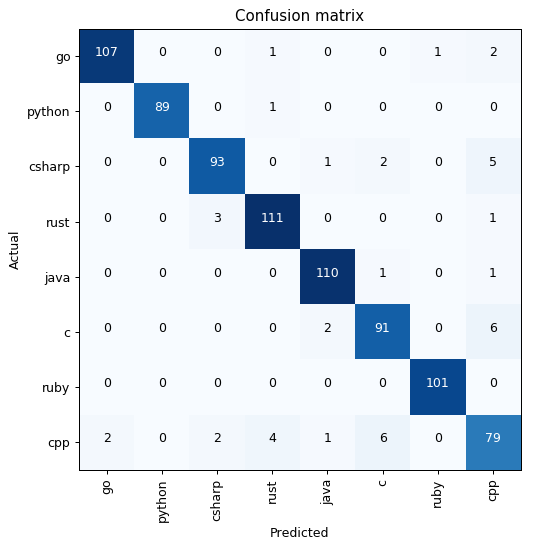
The confusion matrix shows lots of zeroes, which is good, but we can also see that there were some languages and pairs that gave the model a lot of trouble. An example is C++, which was often mixed up C and C#. This actually makes a lot of sense since C++ evolved from C and has in turn influenced C# and Java. Thus these languages share a lot of similar features, making them harder to identify.
There were also some samples which consisted mostly or solely of license headers, making the language virtually impossible to detect. I should also point out that there’s probably some overfitting going on because of the small size & variety of the dataset. Here are some examples of the detection having gone wrong:
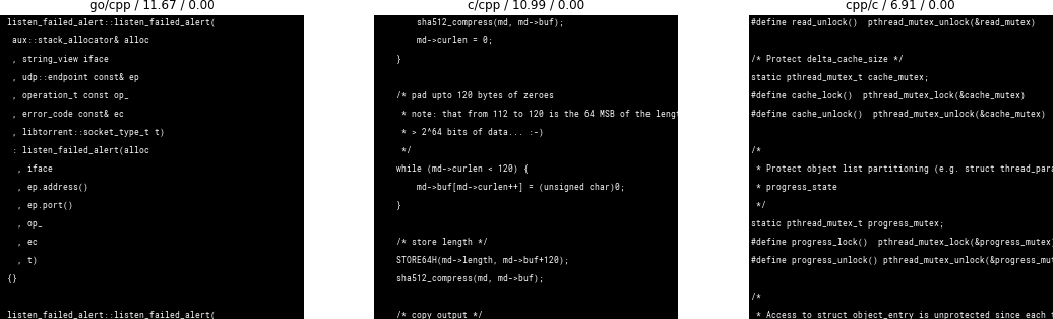
Examples of the images that the classifier was most wrong about
Future Work
This could be extended further in a couple of ways.
First, the dataset used was quite small. 8 projects probably isn’t enough to get a full picture (pun intended) of a programming language, especially if the projects are domain specific and use specific coding styles and conventions. Thus using a larger number of projects as well as a larger sample of source code from within each project could be beneficial.
Additionally, it would be interesting to see how well this works when using real-world images such as screenshots or photos as inputs. The current model was train only on images without any transformations (e.g. scaling or zooming), rendered in one style (white text on black background). This probably makes it much easier to detect characters and keywords specific to source code.

Real-world example of source code image, with blurring, rotation, highlighting, etc
For real-world images, differences in fonts, colors, highlighting styles, focus, etc would all make the task much harder. On the other hand, the used generic image-classification models such as ResNet34 have been trained on real-world images anyway, so perhaps the difference isn’t that big after all.
Ultimately, this could be a mobile application similar to Not Hotdog app. Of course, it would be more efficient to first do image-to-text and then use one of the many existing language detectors… but where is the fun in that? :-)